"Nuggets"
This space is for ideas that are not ready or not well-formed enough for a publication, but for whatever reason felt fun or important to share.
Please keep in mind: I'm just some guy on the internet. It's *possible* that I'm wrong or my thinking has evolved since the time of writing. This writing is to work through ideas, learn, and grow.
The name comes from a deeply influential mentor of mine, Royce Zia. I always thought the name "nuggets" was funny.
2024-03-19

I’m reading a lot about multi-agent systems for a current project and a them that keeps coming up is an “ontology” as a way to standardize communication on a certain subject between certain actors. Abstract, no? Another phrase for this, and one that’s somewhat more understandable, is just a “protocol.” Basically when two computer programs need to communicate we generally establish some agreed upon set of messaging structures to allow them to pack and unpack data. You can think of this like an envelope: certain items need to be consistently handled, such as the address, the return address, stamps, cancelling, etc. but by and large we don’t give a s— about what goes inside of the envelope.
In some of the literature I’m reading, it appears that everyone feels the need to have their own ontology. What’s an ontology you might ask?
"A systematic arrangement of all of the important categories of objects or concepts which exist in some field of discourse, showing the relations between them. When complete, an ontology is a categorization of all of the concepts in some field of knowledge, including the objects and all of the properties, relations, and functions needed to define the objects and specify their actions. A simplified ontology may contain only a hierarchical classification (a taxonomy) showing the type subsumption..."
Ugh. Jesus. In the context of multi-agent systems, it’s a protocol. Protocols in my experience are better for being kept as simple as possible, so if you feel that you need an “ontology” I think you need to do some soul searching about what it is you’re actually working on and what your goals actually are. Furthermore, where I see ontologies cropping up are mostly in computer science literature, which is extra crazy, because none of these ontologies seem to include a version that can be used in real code.
Yes this post is reactionary and knee-jerk, and with everything I say/do/write, I’m happy to be proven wrong. Ontologies to me just feel like the xkcd comic above. Someone has a “brilliant” idea for a new ontology so the propose it, publish it, write about it, maybe even use it, but the value in something like an ontology is its reuse
This one I find especialy offputting, although it looks official. It’s both too literal and too abstract at the same time. Website is not well maintained. No implementations that I can readily find, etc.
To move “ontologies” out of the obscure, silly academic corners, we should be focused on make their reuse as easy as possible for other users. That starts by keeping them simple, and providing tools.
2024-02-08
Specifically, sometime circa 2023. You read it here first.
Look around. Things on the internet feel different these days. We accept that much of our world is algorithmically driven, and those algorithms are likely machine learning on massive datasets of our usage patterns.
The search engines don’t work as well as they used to. Most of them full of SEO garbage. Listicles and ad farms, most of the content for which is likely created by generative AI.
More and more decision making is handed over to machine-learning driven optimizations.
It’s all gambling and loot boxes. Content and media.
Perhaps the “singularity” is a misnomer (at least on one human lifespan), because the transition is slow. Too slow to really perceive. Too fast to have ever had a chance to do anything about.
I love the utility of this site. It’s both cutting edge and so goddamn old fashioned. Anachronistic and inefficient. Like an old steam engine. Full of fire. I manually edit a JSON file over an SSH connection to update the content. We laugh about it. It happens as a single instant in time. A human island in sea of generative noise.
2024-02-07


One of those milestones that comes and goes without too much fanfare, but I think this is the first real presentation discussing core, its implementation and how it compares/contrasts with Simple Mind as a project.
Thanks to Brent Liu and his BME class for having us around to talk about the project! I’m still trying to gather my thoughts around core and it’s good to be required to talk about it every so often.
Rattles a few new ideas loose every time. :)
2024-01-20



Feeling proud today.
Although there is still room to improve, I think I can safely conclude that I’ve achieved my goal of making custom phantoms using 3D printed molds. We’re working on a submission to CT Meeting, so I won’t such much in the way of details here, but here are some photos of one of the phantoms that we’ll collect our published (hopefully!) data with. I had everyone that helped to demold the phantom sign it and very much appreciate their input and feedback on the process. <3
2024-01-03
Last night I poured the first full-sized phantom that I think actually has a change of working. Video above. This uses everything I’ve gleaned over the last week from my small scale attempts, but removes the “small” part, which is an enormous change. Theres a lot about this process that’s different between the two scales.
Tonight’s demolding operation, the demolding of the above pour/attempt, straight up has me nervous. I feel pretty confident that it should go to plan, but the demolding of the inserts at this scale remains completely untested. My main plan, which actually came to me immediately after my last post where I presented a different plan (now plan B), is to fashion a sort of bearing puller with a 3d printed sleeve and a long bolt. I’m pretty confident this is ultimate cheapest and easiest option.
This is also my first experience with the deep pour resin, which has VERY different properties that the crafty stuff I was using on the small scale. There’s really no way to test the deep pour at the smaller scales since it really doesn’t even seem to get hot enough to cure below a certain size, but even the big phantom sort of has a hint of elasticity in the exposed surfaces. And like, I really kind of need this to work… emotionally. Haha.
This has been a weird week. I haven’t been this “in it” for a while, and it’s been fun, but I think it’s for the best that I don’t do this too often. It was actually hard on me.
IYKYK
I’ll post some results of the demolding operation. Keep your fingers crossed. Mainly for the phantom, but also for my sake too. 😮💨
2024-01-02

Being who I am, it feels prudent to mention that I have not yet successfully demolded a full-sized phantom body just yet. But I’m feeling good about the latest design and I’m currently printing up my first full-sized mold that I think will actually have a decent chance of working. So I’m still not finished with the project, but definitely slowing the pace down a little bit.
As you can see from the picture above, this whole approach really hinges on one’s ability to get the inserts out… which has been in many cases unsuccessful or not even worth attempting. 3D printing and resins are unfortunately both working against us here. The 3D printed layer lines add a subtle but significant mechanical lock to the insert molds, and the resin also seems to contract down on insert as it cures, gripping them extremely tightly. Only the mold+phantom in the bottom right hand corner was able to be demolded predictably and “as envisioned.” Everything else was a crap shoot of yanking with pliers, utility knives (not recommended), makeshift pressing tools, vice grips, etc. all in a largely unsuccessful attempt to fully demold these stupid blocks of plastic.
I moved on from my original idea to extract the inserts by exploiting softened PLA (w/ a heat gun) and then twisting. That had a sexy elegance to it (we’re exploiting the thermoelastic properties of the mold material, that’s cool), but PLA will be probably not be a viable option. The last attempt I made in PLA ended up better than expected, but still completely deformed due to mold softening during curing. ABS does not have the same issue due to its better heat tolerance, however printing ABS just kinda sucks (fumes, hotter temps required, less viable on cheaper printer options). PETG is still a possibility and one that I will try after I make sure that demolding is possible with the new mold design. If you can limit the curing temperature of your resin, then PLA may still be a viable option.
Right now, I’m printing the mold for what I think has the best chance of a full-sized success: ABS with deep pour epoxy resin (cures more slowly, but lower heat and I don’t have to do a multi-layered epoxy pour) and mold release on the insert walls. As part of the model now, a threaded insert pressing tool is calculated and included that can then be screwed into the top of each insert and be pressed out with an arbor press or similar. I tried my absolute best to limit the additional tools required (stuff like an arbor press), but I just think that’s going to be the only reproducible, safe, not too infuriating way to consistently get the inserts out without damaging the phantom. A basic arbor press can be had for \\(60-\\)100 off Amazon, so were still well “within budget”, but it does add an additional complexity.
I would’ve liked to have found a way, like the mold walls, to introduce a failure point to the insert walls that can then be scored and removed without the press. That will only work above certain sizes though, as getting a knife in to score the interior wall of an insert when that insert is 1cm in diameter… well I just think a \\(60 arbor press is a decent investment. Please take my chewed up, cut, burned, and scraped hands as a warning to just invest the extra \\)150 or whatever and get what you need.
Any ultimately, this isn’t the conclusion of all this. I’m feeling good about the latest mold design, but it remains to be seen if it can be (1) cast without deforming, and (2) demolded without damage. I’m cautiously optimistic it’ll work but realistically it’ll need some tweaking. My goal now though is to at least be able to get good-enough phantoms so that I can begin to go make the radiologic measurements we need, and I can turn this crazy week into a paper (or two or three actually?).
I started on this thinking it would take 2-3 days before I had something pretty “competitive”, but good lord was I off-base. On the other hand, this has been an incredibly gratifying rabbit hole to go down. I love doing the 3D design and getting to do it parametrically now with Fusion 360, rather than trying to bang stuff out with SketchUp has really opened my eyes. I still have a ton to learn, but it’s awesome to know that I can reach for Fusion 360 now and can finally let SketchUp die in obscurity.
There’s lots to work on in the future too: I realized that I should be able to easily account for resin shrinkage by oversizing the mold just slightly. For prototyping, I had already implemented scale as one of the parameters tuneable in the Fusion 360 project to allow me to easily do 50% size molds, but here we can repurpose for a materials issue. Although I will probably try to publish before I attempt that, this tuning should allow for bang-on dimensions and tolerances if you have a resin that provides you an estimate of the shrinkage such as McMaster-Carr’s offerings.
I’m absolutely exhausted though. Shredded. Like my early inelegant molds. I think I’m gonna go lie down.

While it didn’t go perfectly, I now have proof positive that my ideas aren’t totally wrong here and that this is a totally viable approach to getting maybe, sorta pretty decent phantoms.
I’ve only done the test in the 1/8th scale version and with a very aggressive (i.e. hot, so very non-ideal) urethane. However, I was able to get them cleanly out of the molds… mostly. Those photos are below.
I also poured two epoxy molds that will cure overnight and I’ll demold tomorrow morning. I think those are gonna be A+ super solid. I’m curious how attenuation values will stack up across the materials. I will post a photo or two of those tomorrow morning after I (hopefully) demold them.

What’s most valuable lesson from today’s test is that my “engineered to fail” mold idea worked perfectly. The walls popped right off with minimal effort, and the “twist out” insert forms worked beautifully in PLA. I actually had foreseen the only problem I ran into, which was the need to separate the insert forms from the mold base one-by-one, rather than trying to do the whole base all at once. Oh well! Easy enough to fix and this win feels pretty good.
I also learned a few other valuable lessons:
ABS is still an option if temperature issues truly aren’t overcome-able. I tested a mold today out of ABS, and although it definitely didn’t deform like the PLA under hot conditions, the mold did clearly have some head (phantom “head”) to foot contraction. I’m cautiously optimistic ABS won’t be necessary. Actually, I suspect that it will prove to be inferior if we can get a good cast in PLA without overheating it. It feels more professional to use ABS, but we can actually utilize the properties of PLA to aid in the demolding process (more on that later). And ABS’s tendency to contract as it cools might also compromise dimensional accuracy even more than the casting process. I’m not yet to the stage where I think my casts are good enough to bother starting to measure dimensional accuracy, but hopefully soon. The priority is still getting the casting process easy and repeatable.
Mold release makes for a worse final product and it has yet to really make demolding easier. As long as we can get it to separate (mechanically, thermally, or both!), then we don’t need to worry about how. Today’s test with mold release (aquaphor and mineral spirits, admittedly not the best) showed a generally loss of detail around fine features. The detail from the dry mold is just way better. And the mold release discolored the urethane substantially to a kind of a dirty yellow. Take a look below.

- Breakaway lines in the mold around each module insert will (should) allow for each insert to be twisted out and removed individually, particularly with heat if using PLA. See? Take full advantage of the materials that we’re working with! :D (Won’t lie, I’m pretty proud of this one. I’m sure its a well-established practice somewhere in the industry, but oh well. I came up with it on my own!)
The final, not so amazing thing:
- Dimensions may be an issue. I shouldn’t have tried to measure since these first versions don’t have the process dialed, are made with an unrealistic resin choice for this phantom body casting approach, and were not demolded with the most elegant method (hammers required currently). But the outer dimensions were under the target (100mm) by 1.2mm (1.2%, ABS mold) and 2.1mm (2.1%, PLA mold), and that’s a little bit bigger than I would expect. I’m guessing a lot of it has to do with resin selection, and I’m thinking (hoping?) that this fast curing stuff probably contracts more than something the cures more slowly would. I’ll be repeating the same test on the epoxy bodies that come out tomorrow, and also double checking the print dimensions.
For this to be viable, it either needs to be trivial for me to make these phantom bodies for others or my hope is that it’s easy enough for others to want to try their hand at making their own (or getting a grad student to do it). I know how busy I feel in my day-to-day life, and how unlikely I would be to undertake this sort of effort unless it were well-resourced. I would need it to be easy to understand, easy to figure my own required investment and likelihood for success, and finally there needs to be a payoff (i.e. the printable fleet of free module inserts I now have readily available).
At every step I’m making a deliberate choices to keep things as simple and easy as possible. If I can eliminate a step, I will. Let’s use the easiest, most available printing filament. No mold release? Don’t mind if I do (don’t?)
Energy: yes! Quality: no!
(ok it is supposed to be a scientific measurement device, so we need a little quality… but like, only 🤏🏻)

Workbench photo from the last mold. Only minimal blood loss from today’s efforts (the single-layer brim on the ABS was sharper than anticipated).
2023-12-27
My first attempts to demold a full-sized resin phantom from a 3D printed mold have gone about like I expected them to. Let’s just say that as far as industrial processes are concerned, this one has been a little more destructive in nature than I had hoped for.
The chance that I got this right on the first attempt though was low, so here are my takeaways and thoughts for the next round of attempts:

Start small and then scale up
Although resin is relatively cheap, it’s not that cheap. I probably went through $30 worth of resin for a part this large.
There are reasons that practicing on small parts isn’t ideal since the casting properties of resin are not 1:1 between small parts and big parts, and the mechanical properties of a 3D printable mold are not the same if scaled down. I do think I have a lot of figuring/learning about the molding process itself first (like whether a direct printed mold can be successfully cast and demolded without damaging the phantom body) and small parts can help me iterate faster while I try some of those options, as well as save on materials cost.
Direct molding versus making a silicone mold
The way that the resin casting folks usually do this is by making a silicone mold of the part first, then casting their resin in the silicone mold. I am confident that this would work fine here, however I’m really trying to avoid going this route.
All other things being equal (they’re actually not), the dealbreaker for me is the additional time required to make the mold (assuming the entire mold including positive of the phantom is printable) first, then do the resin pour once the mold has fully cured. The project easily goes from a weekend to a full week or more for someone looking to make this.
And all other things are not equal. Silicone molding adds to the project:
- Another purchase requirement
- Manufacturer
- Chemical composition
- Durometer
- Point of complexity
- Not all silicone is compatibile with all resin
- Silicone must fully cure otherwise can inhibit part curing
- More complex prints
- Time, energy, uncertainty, “babysitting”
- “Wasted” prints
- Must have a positive of the part to cast a negative
- Positive is waste after mold is made
- Mechanical and tolerance uncertainties
- Many silicone rubbers sold for moldmaking are quite soft
- Soft silicone potentially allows for undesirable mechanical deformations during the casting process
Now what a silicone mold would do for us:
- Reusable
- Make phantom bodies for sale or out of different materials for testing
- Uses the more industry-established method
- Lots of resources online (e.g., YouTube) describing this method
- Less likely to damage the phantom body during demolding
Although there are a lot of downsides, the reusability and damage considerations are worth weighing. I’ll discuss below.
Destructive Molding
Today I think I have two options:
- Begin work on the full silicone molding process
- Accept destructive demolding is the temporary pathway forward and design for it.
Due to the time, design effort, process testing, etc. required to develop a silicone mold workflow (and all the additional cons above), I’m opting to continue with my direct 3D printed mold attempts, but I plan to redesign the molds to intentionally be destructively demolded.
Today’s mold design changes:
Reduce wall thickness. Wall thickness on this first attempt was way too high. Although it made for a rock-solid mold, that’s not a feature when the mold is supposed to be broken in order to be removed.
No wall infill. Infill tends to add mechanical strength, however we ideally are able to deform the mold a little bit in some key ways to get it off easily. Basically I’d like to be able to peel the outer layers off, and this will be easier without infill.
Intentional mechanical failure points. 3D printing is actually pretty strong? If I think through the process of demolding and how I’d like the print to come apart, it’s possible that I can design in some failure points to make the destruction process all around a little less destructive.
Future Versions
Given that having a reusable mold, and a slightly more sophisticated version of the process is one-day desirable, I think I will explore this process as time allows. I suspect that potentially broad adoption of this project is liklier to depend on a quick pathway for potential users to get some results, and importantly the phantom body is not a result. The results of this project are the measurements folks start (potentially) providing on the 3D printable modules that can be inserted in the phantom body.
Although I’m worried about the phantom body, other folks really shouldn’t have to be. I’m hypothesizing that potential users will want the fastest and easiest way to end up with a phantom body, up to and including purchasing one. For that reason, manufacturing the phantom body should be as simple, cheap, and easy (few steps), as possible; silicone molding is fundamentally an obstacle to that.
2023-12-26
At the nudging of one of our students, I’ve undertaken a holiday project of trying my hand at making a real phantom. I’m personally not a huge believer in the current predictive value of texture measurements in CT imaging. I agree that maybe there is something to be measured, but I’m a believer that the features that are important should be motivated by our understanding of the biology and the capabilities of our imaging system, not retrospectively mined and then correlated with certain outcomes through machine learning. I hope to be proven wrong here, I just think part of the problem with radiomics is that ten years on now, we have yet to see the broad use of radiomics tests for the diagnosis of disease. Please feel free to reach out if I am way off base here, I just don’t know if it happening anywhere outside of of specialized research institutes.
One of the things missing from the field right now is any easy way to measure consistent radiomics features. I’ll save the details for the journal article, I get why no manufacturer wants to try and make a texture phantom. If they won’t make one though, we don’t have a shared standard we can use to compare against leaving us all with literally no way to compare between groups. I feel like there’s an opportunity for 3d printing to offer a reasonably easy-to-access alternative to a vendor-provided standard. We provide literally all of the designs required to manufacture your own phantom, including a base library of texture modules. Although we wouldn’t be able to standardize materials perfectly, we take the approach of favoring more data collection (any data collection) and utilizing filtering to sample subgroups as needed. I think lots of people are going to take issue with the approach, but hopefully they can still see that although they may not like the approach, it’s still valuable to those that want to at least attempt to standardize.
Here are a few photos from the initial work:








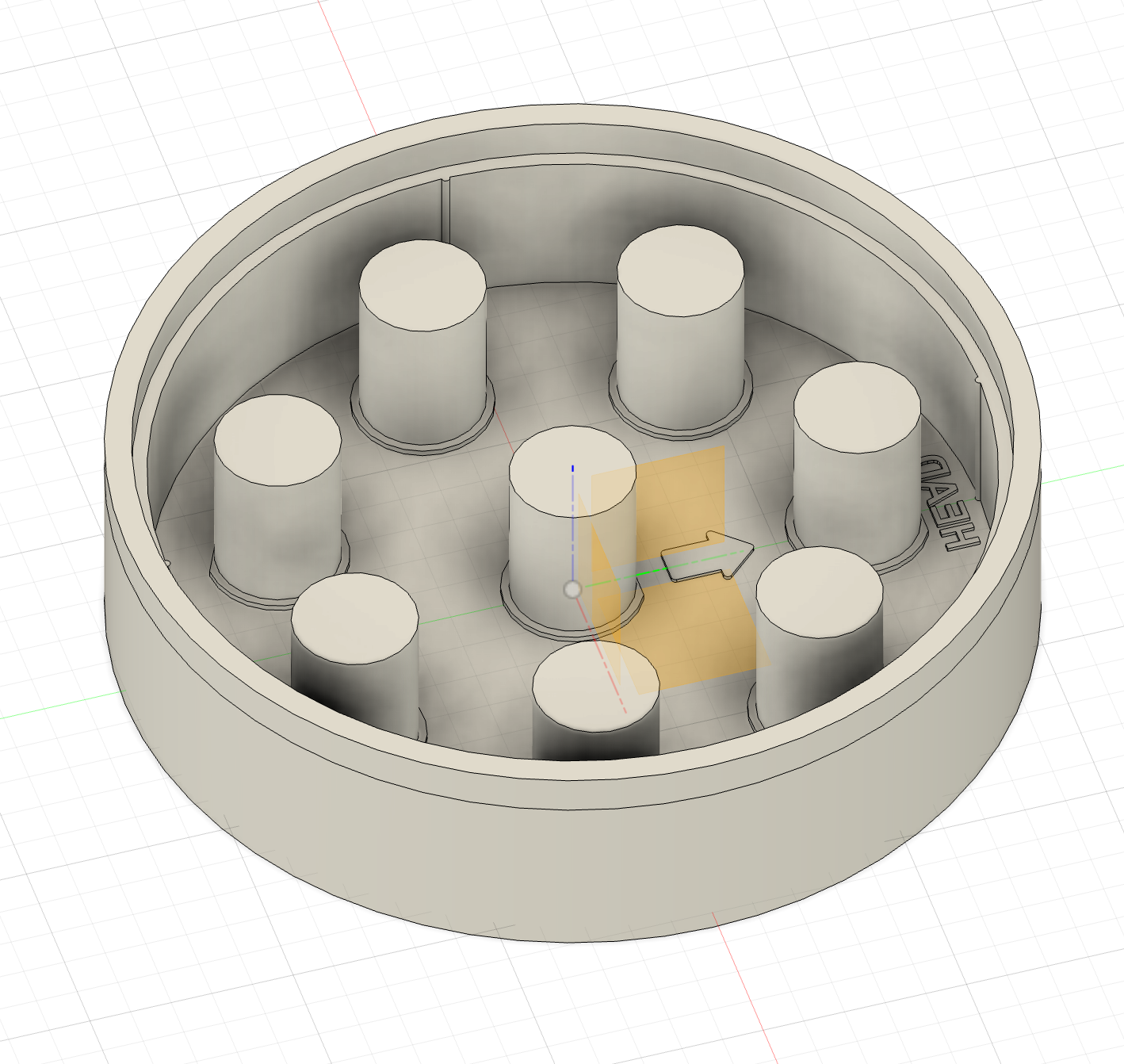
Top row (left to right): Printers (Ender 3 S1 Plus on left, Ender 3 S1 on the right) in action; close up of Ender 3 S1 Plus printing the phantom body mold; resin casting equipment ready - degassing vacuum chamber and vacuum pump on the right.
Middle row (left to right): resin cast in progress (pretty rough looking, hopefully will get better with further attempts; the king; the queen.
Bottom row: render of the (eventual) phantom body; insert “cage”, in which different structures can be built; the 3D printable resin mold for the phantom body.
My first advice on GUI programming is think long and hard about what it is that you’re after. GUIs are this weird slice of computing that are utterly game-changing in many applications, but are a branch of programming unto themselves that has a fairly high cost of implementation and maintenance that can interfere with your ultimate objectives, depending on what they are. However, knowing the basics and being able to build simple GUIs with some minimal functionality I’ve found to be useful for building visualizations and simple, interactive tools to accelerate my own work. I’d like to organize my thoughts on some of the stuff it took me a while to figure out on my own.
One of the simplest but weirdest concepts to get used to is that underneath everything, a GUI is just an infinite loop. Somewhere down there you’ll find a for {...} or a while (true) {...}. What that literally means, is that every GUI framework at the end of the day is just doing something like:
for {
// Read input
// Calculate update
// Redraw screen/application
}
A lot of higher-level GUI programming, such as you’ll find in MATLAB, matplotlib hides this from you. While it does make it faster to bootstrap many application-style GUIs, it requires you to understand callbacks and events. Callbacks are just procedures that you set to occur when certain events are triggered. These events can come from a lot of places, but generally they through user input of some sort, such as clicking something in the window (e.g., a button), pressing a keyboard key, resizing a window, etc.
For today, I’d like to introduce the idea of the multiple different approaches to GUI frameworks. I’m going to describe the one I most commonly come across in my work: “retained-mode” (had to look that up on Wikipedia). It’s object-oriented and the concepts translate well between different libraries such as matplotlib, MATLAB, Qt, and others. The other GUI mode worth looking into is an “immediate mode” GUI. Both are useful and have their roles. I’ll provide some links at the end.
In many ways immediate-mode is actually a little easier to understand exactly how the GUI stuff is done, while retained-mode requires a little more up front knowledge of what’s going on behind the scenes.
I’m also going to keep this high-level: introduce the concepts but not go into detail.
Concept 0: The Event Loop
Concept 1: The Figure (Window)
The top level object for all GUIs is the Figure or Window. I’m going to call it figure since Python or MATLAB are fairly (perhaps unfortunately) dominant. The figure is the top level object and handles the interface between the operating system and the contents our application. This includes important user events like keypresses (keyboard) and cursor events (mouse), which we’ll likely want to interact with. Typically it also provides some resizing functionality, maybe set the background color, etc. Finally, the figure is our container for everything else, including user interface (UI) elements such as text boxes, dropdowns, menus, etc. as well as our drawing-oriented containers such as axes or a framebuffer.
fig = plt.figure()
...
fig.canvas.mpl_connect("key_press_event", on_press)
fig.canvas.mpl_connect("scroll_event", on_scroll)
Concept 2: The Axes/Framebuffer
We can’t (or don’t by convention) draw stuff directly into the figure, we first must add something that is specifically intended for drawing. In MATLAB and matplotlib, most of our drawing is done into a set of axes. In lower level graphics programming, we generally call the analagous data structure the framebuffer or a renderbuffer (it’s not a perfect analogy, but that’s well below the level we need to worry about right now).
Axes provide a lot of functionality. I won’t delve into much of it here, but the docs are a good place to start
2023-11-30
Welp. It finally happened. I got COVID. The canary in the cavern has died. Oh well. Nothing to do at this point but hunker down and wait for it to pass. I’m freshly boosted (almost exactly 4 weeks out) so hopefully it’s uneventful.
I had a good time at RSNA this year, where the COVID was acquired, despite my brain’s best efforts. CVIB folks can regale others with my tales of drinking with an Alaskan fisherman in a dive bar because I got a dinner time wrong. Take the details with a grain of salt: I’ve already heard several versions that have really oversold my drinking abilities. Despite the fun (it’s a pretty silly story, that I’m only a little ashamed of) I also still stand behind my attitude that it’s difficult for me to get much out of RSNA academically. Although I am vocal about it, I found that a lot of people broadly shared this attitude. So isn’t it weird that we all force ourselves to go be uncomfortable with one another in big rooms of other ostensibily uncomfortable people?
The time I do spend with others is “expensive” for me energy-wise and that forces me to place a lot of weight on the committments I do have and work to keep, and I just think that RSNA the conference is probably not going to be one of those committments going forward. Most people say that conferences are about the people that you see while you’re there, and I wholeheartedly agree. Me and all my 49,999 best friends packed onto a massive showroom floor. For real though, in our (not so) “post”-COVID era, I am now really starting to appreciate something like a conference to be in person with other science people is important. And dare I say also, maybe a little bit fun. I honestly think I’ll switch to what I did for DEFCON this year and go to the same city, visit with everyone, but not even pretend to go to the conference (or wear fancy clothes).
Maybe that’s it: the pretense of the conference for me feels a little silly and wasteful of my delicate social reservoirs. Definitely not true for everyone else, but I’m realizing it for myself. It’s complicated. Or maybe not. It feels complicated, but maybe it shouldn’t be.
I do finally feel like I am in a community of people and that is really great. I used to go to these conferences and be alone and miserable for 4 days, so to have too many places to be and people to see is kind of a surreal contrast. I think I’d like it all more if I could just skip the fancy clothes, small talk, and sales pitches and be with those people.
I’ve been fighting with an open issue in core lately trying to add support for “nested attributes” (not important what that means), and ended up basically writing a blog post while organizing my thoughts on it. If you’re so inclined to get a little more detail, you can (maybe, permissions) read it here. Some of this is copied from there.
In short, the Simple Mind group proposed a workaround (that I had opinions about) for core’s lack of support for a much-requested feature. I had told them that said feature (nested attributes in agent specifications) really couldn’t work because of our use of protobuffers and its lack of support for a general, convenient dictionary-like map. Essentially I was having a moment of “but that’s not how you’re supposed to use it!” without offering any evidence of that usage being an issue. No, it may not be how I think they should be using it, but… so? If it’s not hurting anyone, why is it an issue? It’s not.
And I was also right: I have been fighting protobuffers at every step of the process adding tremendous, likely brittle, complexity to code that needs to be as close to 100% reliable as possible. I can see a world in which we get the code working with protobuffers, and then pray that we don’t have to touch it or look at it ever again, but that’s not really a great strategy if resilience is anywhere on the roadmap (which it is. it must be).
Looking at the full extent of the changes, I strongly believe that at this stage the usability benefits of nested attributes do not outweigh the amount of code required to support them, even if I could get them working (which I haven’t and won’t). The true importance of nested attributes is not 100% up to me to decide, since I’m actually not using the feature as much as others. Others may think it should still be included, but ultimately core priorities also matter, and for now, the code cleanliness and maintainability need to outweigh the usability.
Related, but different, unlearning the desire engineer solutions for problems that don’t exist when writing software is so difficult.
In this case, implementing nested attributes has been me trying to prevent someone from putting a hand on a hot stove… except not only has no one been burned yet, the stove may be off, and I don’t even have strong evidence that the stove exists. Hunches are valid, but we/I need to be careful to not confuse hunches with evidence of a problem. One merits caution, one merits engineering. In this case, I think there’s a world in which I’m right, and things do get complicated for the folks that work around us. Or, equally likely, they try something and figure out where it does and does not work, maybe even come up with a solution no one had thought of. For me, there are literally no downsides to encouraging them take their approach. At the very least, it frees me up to work on the stuff I’m really interested in.
Although I was trying to help with nested attributes, my attempt here was… misguided. I think it ultimately came from a place of wanting to steer user behavior rather than enable new functionality in the software. I’m still trying to get better at letting things evolve organically rather than try to intervene. I saw something that I thought might be a problem, but ultimately is not currently, nor is there strong evidence that it will be a problem in the future. I should’ve sat back and let them do their thing.
Permissiveness and the ceding of control is an important principle of the current implementation of core. I’d like to also see permissiveness be a core development philosophy/idea as well. I’m planning to write more about this at some point in the hopes of turning some portion of it into a journal article.
For core, it’s not up to us how you use the blackboard, we’re here to make it possible for you to use the blackboard as best as you possibly can. We don’t have to support every use case, but we also shouldn’t get in the way of unforeseen usages… or start engineering something because we think it’ll prevent someone from doing something a certain way. In this case, I think I got it wrong, but better to pull the plug now (sunk cost fallacy) than to plod on indefinitely.
2023-11-19
During CT Lab yesterday, I remembered that, at some point, I made this video visualizing backprojection CT image reconstruction.
I don’t remember really any of the details (the exact algorithm, what’s being reconstructed, number of projections, etc.) but it’s a good overall representation of the summation inherent to the reconstruction process in CT. We start out with a grid full of zeroes, and then slowly build up the image projection by projection.
You’re (sort of) seeing the reverse of the process used to acquire the images. Because signal processing, we have to filter the projections before the summation (which although visualizable, is not well represented in this video).
Anyways, trying to get better about sharing this sort of stuff from my day-to-day work.
2023-11-19
During CT Lab yesterday, I remembered that, at some point, I made this video visualizing backprojection CT image reconstruction.
I don’t remember really any of the details (the exact algorithm, what’s being reconstructed, number of projections, etc.) but it’s a good overall representation of the summation inherent to the reconstruction process in CT. We start out with a grid full of zeroes, and then slowly build up the image projection by projection.
You’re (sort of) seeing the reverse of the process used to acquire the images. Because signal processing, we have to filter the projections before the summation (which although visualizable, is not well represented in this video).
Anyways, trying to get better about sharing this sort of stuff from my day-to-day work.
2023-11-07

This is a fishing story.
I’ve been making big changes to my home server/lab configuration. In some ways, I am downsizing, but in other ways, very much upsizing.
On that journey, one of the ideas I’ve been playing around with is virtualizing a lightweight gaming machine on my monster Supermicro MBD-H11SSL-NC, which now virtualizes all of the servers in my apartment. I want to stream Dwarf Fortress to my Macbook since the Mac version is not a high development priority, and DF tends to drain the battery pretty quickly, the computer gets warm, etc. The usual reasons people virtualize machines.
Dwarf Fortress is a CPU-intensive game but not graphically demanding, so I was optimistic that software rendering could handle it. Although it wasn’t so atrocious at about 10 FPS, that’s not quite good enough to be “fun” to play and worth the other potential tradeoffs. So I’ll need a GPU.
GPU passthrough is a necessary evil when virtualizing something like a gaming machine. It’s also required when you’re doing containerization for my main work area of GPU computing in medical imaging (AI and CT image reconstruction). Good docker images have helped that effort, though, and it’s a somewhat simpler prospect. GPU passthrough assigns the GPU to the virtual machine. However, it’s non-trivially finicky to ensure the virtualization host operation system doesn’t try to control them. If the two different kernels (host and virtual) both try to control the device, well, the device goes offline until you either reset it via the command line or reboot the machine.
Since this motherboard controls all of my homelab, including router + DHCP, wifi, and NAS, rebooting is… undesirable. It’s a proper server motherboard, too, so it takes 3-5 business days to boot (3-5 minutes, but the whole network goes down, which also makes it difficult to monitor).
I started with what I had on hand: an RTX 3060. Although I was able to get this running (inelegantly and with all the usual Nvidia-on-Linux baggage), the power draw was way too high for something that’s going to sit in a server that’s on 24⁄7. Power will end up being a significant cost relative to the price of the machine during it’s lifetime. It will cost me about $1000 to run this system over the next four years. Although I did get the game running on the GPU, the setup never quite worked 100%. I could only get DF up to about 30-35 frames, so between that and the power draw, I gave up quickly on my existing cards.
I specifically don’t want anything fancy; even the RTX 3060 is overperformant for this application. I need something minimal that the CPU can offload simple frame generation to. My favorite games are Dwarf Fortress, Factorio, and many more “indie” type games. The only AAA stuff I play is ten years out-of-date by the time I get to it.
I ended up settling on a low-profile Radeon 6400. I’ve heard AMD support on Linux is excellent compared to Nvidia, and my irrational unwillingness to have Windows computers in my home requires that I game on Linux. It also idles at around 10 watts, which is tolerable. I had a couple of card-level crashes before I got it fully disabled from the Proxmox, but after, you know, following the instructions, I haven’t had any more crashes.
Gnome has been the last hurdle. For reasons not worth explaining, I want/need to use RDP to connect. The other options are either dumb (Teamviewer is dumb and a bad company) or not well-supported anymore (VNC). Gnome RDP works well. I learned the hard way, though there are two limitations, one soft and one hard:
- The RDP password resets between reboots, which is not ideal for a system that is intended to run headless (can be worked around, but Jesus Gnome, please figure this out)
- Current Gnome RDP does not support “headless” mode… this is a problem.
Although I didn’t have it working 100% correctly, I managed to get a round of streaming DF in, and I couldn’t tell that I wasn’t just playing it locally. That was pretty damn cool! DF’s unique design hid some of the crimes of the setup, but it was good enough that I stayed up way too late playing it! And it barely touched the battery on my Macbook Air (the real victory here).
The final issue in all of this is that although RDP does have a real “headless” mode where the client sends its display information over, Gnome does not yet support this (here and (here)[https://gitlab.gnome.org/GNOME/mutter/-/issues/1605]). Although xrdp is an option, with the transition from X server to Wayland, a lot of related stuff is actively breaking, and I worry xrdp will eventually break, too. I just suspect the version baked into the desktop environment will be better supported going forward, and this is a critical feature for me.
So it all has come down to just buying a dummy display adapter, which probably would’ve made this all way more manageable from the beginning. It’s one of those frustratingly inelegant solutions, but also, in this case, it’s the perfectly fitting final piece of this puzzle. It’s amazingly functional but somehow still disappointing.
It’s pretty wild how well virtualization works these days, especially considering how recently a lot of the PCIe passthrough development has been done. It still could be a pleasant experience for GPUs. The most frustrating part for me is not being sure if the problems are configuration-related or a fundamental limitation in your setup. So it just takes fishing. And more fishing. And more fishing. Until you land something that you can live with.
I now have a much better sense of the exact configuration and the setup I want/need. I have run into this last issue, but am 95% sure that the display adapter is going to fix it, and I’ll have the exact experience I’m looking for. Honestly, it’s taken a ridiculous amount of time and work to get this running (and money, too, a wee bit more than your average $100 Best Buy router), but I’ve learned a boatload in the process. Between this and my last project (seen in the background of my current profile photo), some of the details of networking and network configuration have really crystallized for me in ways they hadn’t before. Virtualizing everything really elevates that to the next level and has been a fun project over the last few weeks, if sincerely trying at times.
Streaming Dwarf Fortress with perfect frame rates and update times without heat or slowdowns is sweet. Really sweet. And I can always add more cores if it isn’t! Like 58 of them if I need it!
UPDATE: It was all a lie. The dummy display didn’t fix it. I ended up plugging in a 10” 1080p monitor I had around that now lives its life to support this effort. Never did get OS-level RDP working so I’m using Steam Remote Play. It’s now much better with the GPU working correctly b/c of the connected monitor. So like, it’s actually a very tidy solution, but just not the solution I feel like SHOULD be the solution. Dumb. 😅
We’ve put in a lot of effort lately to bring Simple Mind’s communication backend up into 2023. My hope is to make the project available publicly shortly, but I think we’ll need to do some soul-searching on what exactly the strategy is for this. I can’t support it like a full-time team could, so putting it out in front of people too soon and making too much noise before it can really deliver is definitely a concern of mine. I’m really proud of this architecture and think it could be really quite powerful for certain types of computing jobs. I would honestly be spending most of my time on in right now if I didn’t have other committments.
While it’s ultimately fairly simple engineering, I feel like the abstractions that Josh and I arrived at are really powerful. The architecture really simplifies the process of communicating data between entities. I also think that the whole architecture is more than just an event stream; the agent API (i.e. client-side API) is also very simple, but stripped down to the bare minimum to support the scientific use case for a blackboard. The openness and simplicity of it all (more below) also allows for super easy deployment and configuration.
Part of that “stripping it back” process was to remove security as a consideration (at least for now). Although any business use case would require it, we’re not actually doing business and working outside of that mental space is deeply freeing. Let’s not get it twisted: I am very pro-security, but I see this as a key engineering decision to focus efforts on the architecture and performance of the system at this moment. Basically, we choose to be completely open and publicly accessible on the local network. At this point, no HTTPS either. Essentially, your only option to “secure” our system is to firewall it off away from other computers. I’ll probably write more about this later… I have a lot of thoughts here.
Performance is already a semi-known concern. We have an open ticket to accelerate an initial example the uses chest x-ray to demonstrate the basic idea of how Simple Mind works on our architecture. I haven’t had much of a chance to really dig into what the current issue is, but there are a lot of places we could be struggling. We can crank up network bandwidth to begin (the mini datacenter I built to prototype a dedicated hardware environment uses 2.5Gb networking, but would ideally be higher), but I still worry that we’re going to hit HTTP stack limitations at some point. Mainly, I haven’t aggressively gone after parallelization in the networking code, so there could be an opportunity to maximize throughput there. The server should be plenty parallel (each request on its own goroutine), but also it’s fully handling the upload/download of all data which is definitely probably hurting. I think putting bigger data into an object store and offloading the transaction cost to an optimized system (like MinIO), should hopefully alleviate a signficant amount of server pressure.
The quickness with which the CVIB graduate students picked up the system was really great. I think part of that is that they’re a smart group of folks, but also even smart people sometimes need more than a few hours to get the basics up and running. My goal with the core system is that you can be up and running with a reasonably complete python example within an hour, and although there were a few hiccups in the kickoff, I’d say we weren’t horribly far off from that point, but still have a little ways to go. I think as certain ideas crystallize, it’ll get more obvious where we need to beef up documentation around core features.
The extensibility is the last thing that has worked incredibly well. The number of new agents that folks were able to write and produce over the course of a few days was exactly what I was hoping to achieve. That’s how easy it should be and is a big improvement over the previous version. The other open source implementations of the blackboard architecture that I’ve seen as well as the wikipedia description suggests that folks have often taken a strongly coupled approach between the blackboard as a datastructure and the problem domain in which the developers are working. There’s nothing inherently wrong with this (specifically in terms of the blackboard as a more abstract control architecture for problem solving), however I don’t see any actual good reason to do this, and any communication between the independent agents (writing to the blackboard) and the blackboard itself is not reusable. Identifying and using better interfaces between components, and seeing the communication problem as separable from the actual domain problems has allowed us to build an underlying system that can be repurposed for any application.
So all of these aspects of the project are really quite exciting, but figuring out what, how, and where to publish the work is eluding me at the moment. I also sort of feel like we need at least one big “win” for the system before we should make any noise at all, since right now it’s just slightly better than a proof-of-concept. I definitely feel confident that we can get there though. I’ll be trying to write a few more of these to see if I can find the right thread to pull on.

2023-07-20
Hey this is a test to try and get this to work?
How should I parse markdown in Go?
does bold work? What about italics?
I’ll want to get some latex support up sometime soon.
And the ability to write javascript blocks too that render correctly. Maybe a canvas?
Gonna be a wild ride.
2023-07-19
Hey this is a test to try and get this to work?
How should I parse markdown in Go?
does bold work? What about italics?
I’ll want to get some latex support up sometime soon.
And the ability to write javascript blocks too that render correctly. Maybe a canvas?
Gonna be a wild ride.
2022-12-06
Full disclosure: I hate conferences. Even the ones that I like, I’d still rather be just about anywhere else.
My personal reasons mostly revolve around being completely overwhelmed the whole time I’m there, exhausted afterwards, not eating right, and just generally seeing my anxiety spike before during and after a(ny) conference. My personal situation is now further complicated that I have celiac disease; that’s not entirely the conference’s fault, but not offering gluten-free options other than that sad, shitty, overpriced Caesar’s salad is.
Although this year’s RSNA was more fun than previous years due to a good core group that attended, my first post-COVID conference left me feeling pretty bummed out about some bigger picture stuff and lessons we could’ve learned from COVID and the shutdowns, but clearly didn’t.
Issue 1: Primary function of most conferences is social and business
I don’t really have a problem with this, I just wish we would just admit this up front and drop the pretext of “science” at bigger meetings like RSNA and AAPM. The talks are also all so stacked on top of each other, you could never possible attend the ones you want. And 7-8 minutes? Comically short to try and convey anything of substance.
My guess is that the talks and the posters are merely pretext to get folks to attend with their institution footing the bill. That’s wasteful and not a particularly good way to convey science. If we want to fly someone halfway across the country for science, we should make it A LOT more worthwhile than 7 minutes.
Issue 2: The travel required is horrendous for the environment
Although this year was still smaller than 2019 numbers, I think RSNA is attended by like 50k-70k people in most years. The amount of travel required is ****massive**** to get everyone there in person. Its not uncommon for someone to fly in to give their talk or take a business meeting, and then turn around and go right back to the airport. Oof.
I don’t think our environment can really take that sort of thing much longer. And think about all of the conferences that happen. Who is that really serving? I think as scientists we really need to start thinking about this more critically with all of our travel.
Issue 3: COVID and other illnesses
This truly surprised me: at a conference almost entirely attended by doctors and folks who work in healthcare, I’d estimate that less than 1% of people were masking. The one scientific session I was able to attend had a guy who couldn’t stop coughing and clearly had some sort of respiratory illness. WTF man? Go home. Stay in your hotel. Don’t go sit in a conference room full of people.
In previous years, I picked up at least one or two illnesses at conferences (DEFCON had the running “con-flu” jokes that got a lot more real post-covid). Should we really be convening tens of thousands of people from all over the world right before everyone goes and travels for the holidays?
I feel like scientific conferences should leave their attendees feeling at least somewhat enriched and like they’ve learned or encountered something new (that’s not a novel viral illness.)
My takeaway from RSNA this year? We’ve learned nothing over the last 3 years.
The deeper you go into any field, the more you start to see the frayed edges, the human touches and imperfections that aren’t visible to the newcomer or the outsider. Blah blah blah, something that sounds like it came from a TED talk…
I mainly just wanted to document what may be an oversight in two pretty mainstream image analysis packages.
As part of my latest round of work on FreeCT, I’ve been adding support for the NIfTI1 file format. Inside of the header there are two float fields, scl_slope and scl_inter, that should allow for rescaling of your voxel values according to the the standard. I intend to use this to reduce the storage footprint of reconstructions from FreeCT, mapping our 32-bit floating point data into 16-bit unsigned integers.
This is super convenient since for most CT applications 16 bits is enough depth to capture the dynamic range. If you’re using Hounsfield units, you can get away with 12 bits typically, however I’m not going to assume that we always want Hounsfield unit output. The reduction to 16-bit integers has the further knock on benefit with NIfTI of improving gzip compression, since we’ve reduced the Shannon entropy of our dataset (pretty sure I’m using that term correctly here.)
There’s clearly some pretty significant gains to be had here: by using these fields I can reduce the output storage requirements by more than 50%. That’s 50% fewer drives to buy, less power usage, fewer servers, etc. But there’s a problem: ITKSNAP and ImageJ don’t seem to use this field to rescale their value correctly, meaning any analysis that someone would want to do with these tools would either be (1) incorrect, or (2) the user would have to preprocess the data into something like MATLAB and manually apply the rescale. Neither of these options is particularly acceptable in the modern era of FreeCT that’s focused on usability.
Now, I’ve learned over the years that if you think there’s a bug in a library, there’s actually not and you’ve just made a mistake somewhere in your code (joking of course… mostly.) Based on that, my first inclination was that I’ve misunderstood something about the standard or made a mistake in my implementation, but the fact that 3DSlicer does read and use these fields correctly (in the same file) means that there’s clearly just differences in support for it between the different software packages.
I’m left with a choice: forfeit these potential gains and just use the underlying float datatype that NIfTI does support, or do it the “right way” but ultimately end up with a somewhat limited tool. I’m going to go try and blast some message boards and/or some Gitlab/Github “issues” pages to see if I can get some clarity.
2022-09-24
I’ve been accidentally receiving a few copies of New Left Review and finally got around to reading one of the key articles the jumped out to me. It’s a rather dense philosophical and economic look at the different arguments and inquiries into the technological world we currently live in, and whether or not it is “capitalist” in nature or something else, namely more “feudal” in nature. If this sort of topic is interesting to you, then it’s well worth a read. My interest in writing about it here is trying to tease out what I think the author (Morozov) was driving at and how that intersects my own experience.
Being fairly philosophical/theoretical in nature, a fair bit of time is spent on providing strict definitions and interpretations of the various systems (i.e. capitalism, Marxism, feudalism, etc.), but while I was reading, I kept coming back to the same question “what value does does a theoretical definition of any of these systems hold when the practical application looks nothing like these definitions?” It took me until the last sentence of the article really understand my question was exactly where Morozov was headed all along: “[There] is not reason to believe that techno-capitalism is somehow a nicer, cozier and more progressive regime that techno-feudalism; by vainly invoking the latter, we risk whitewashing the former.”
My own personal experience working in the tech industry, and now academia, is that theoretical capitalism, like Marxism, has not ever (perhaps cannot) functioned without extra-economic leverage (e.g., in extreme, but not uncommon, cases violence, but more commonly using political and economic power, such as monopolies, that technically lie outside of the fundamental system.)
For instance, to get any job in my field, I must agree to sign over intellectual property rights to anything that I create to my employer; disappointingly, this has proven true in academia as well. And while you may thing “yeah, that makes sense because they’re paying you,” many employers seek to own your creative work outside of work hours as well (although to varying degrees of success). Not coming from “means,” I’ve never had the opportunity to create anything without having a steady paycheck. Although I’m certainly not suffering in life right now, I don’t have the luxury or truly the ability to buy my way out of this system. I could do so temporarily, but when the time comes, I would likely have to sell the ideas I create to the highest bidder. I would not be able to fend of a strong competitor or potential legal challenges on my own, without the “means” (i.e. money) of an interested third-party.
For me, it is arbitrary whether we call this capitalism or feudalism. I guess in a truly “feudal” system, I could be coerced with a wrench applied to my kneecaps, which is (at least for the time being) still somewhat frowned upon in our “capitalist” system. But are capricious legal, financial, or ethical means of coercion really all that much better? If the last few years are any indication, I also don’t think we’re all that far off technological forms of wrench-to-kneecap styles of leverage, such as doxxing, and leaking search and email histories. And I have an huge edge in that I know and understand these technical systems much better than the average person in our society. I can guarantee you that the folks who don’t understand them care a lot less about what we call our current system, the point is the same: it’s not working for anyone anymore other than the few at the very top.
2022-07-07
Another thorn in my side since starting FreeCT is how to configure a reconstruction. It’s inherently complex, and there are dozens of parameters that go into a CT reconstruction specific to the scanner, the scan, and the desired reconstruction output. It’s way too many for a command line, so the original approach was to use a YAML config file. BUT, config files are annoying when you just want to tweak one thing or vary a few parameters. Moreover, some config parameters are going to change from one recon to another, but others (many) are going to stay the exact same. Finally, many of the parameters don’t vary (e.g., scan geometry), and are probably provided by the raw data, so how do we extract and use those? Also, how do we know all of the different parameters that a reconstruction needs to do it’s job?!
I think the ideal solution comes down to the following:
- We have to use config files for the bulk of the input data,
- A reconstruction program must be able to tell the user what it expects as inputs and when possible, provide suggesting inputs based off of the raw data, and
- To make actual use of the program easier (particulary for the sort of work my research group does), ANY config parameter should be override-able with a command line switch (e.g.,
-recon.slicethickness=0.6)
I first started playing with Viper and although it would provide all of the basic functionality I need, I can’t quite figure out why it’s better than rolling my own. It honestly seems like I’ll end up with the same amount of code for this particular use case, but in one case I’ll have this fairly large dependency. Furthermore, I realized that I actually didn’t really clearly know what I wanted from Viper, so I decided to take a step back though and think more critically about how I would like to use the tool that I’m building.
With FreeCT, you generally start with some raw data, typically stored in some binary or pseudo-binary format like DICOM. You likely don’t know exactly what’s in that data, and thus, don’t know what to configure from the get go for any particular reconstruction. So the first step, is we need something to extract whatever metadata is in that raw data (scan geometry, initial reconstruction values, etc.). If we only have binary data though, we’ll still need a way to generate the basic config so we know what all the program is expecting, even if we have to manually enter it (useful for simulation studies). This leads us to our first design requirements:
- FreeCT recon executables (e.g. fct-wfbp or fct-icd) must support an
--empty-configto generate an empty configuration file for the program - FreeCT recon executables must support an
--base-configto generate a prepopulated “best-guess” config file from some raw data
As a “gimme,” we also have:
- FreeCT executables shall all use the
--config={config-file}parameter to specify their configuration input
Go also makes it very slick to serialize into and out of structures using “tags.” Thus:
- Every parameter used by any FreeCT program must be backed by a serializable structure (JSON and YAML must be supported)
- Each executable shall define its whole config format using composition of such serializable structures
- Each executable can add a set of parameters specific to the reconstruction method (e.g. WFPB will accept different input than an iterative method)
Finally,
- Every configuration parameter must be overridable from the command line
- Command line overrides shall follow the format:
--{block}.{parameter}={value}, with a little nesting as possible. E.g.:--recon.slicethickness=0.6or--wfbp.kernel=smooth. - To facilitate “universal” support for this approach, FreeCT should provide a config package that implements the above design requirements; individual reconstructions should only need to implement support for method-specific parameters and then inject it into a base configuration
With the above requirements, I feel like I have a much better sense of what needs to be done and how to approach it.
2022-07-05
As part of my rewrite of FreeCT using Go, I’m really doubling down on trying to get support for different raw data types correct. The problem is that there’s no standard format for CT raw data, and even vendors’ proprietary formats change over time. The underlying data is mostly the same though (projections, geometry, etc.). Raw data has long been a thorn in my side with FreeCT, and an issue that never got the love it needed. It’s also important that whatever I implement stays extensible so that I can easily add support for other data types in the future, since it’s tough to predict what we’ll need to support.
Go’s interfaces are perfect for this, and in many ways I think it’s serving the same function as the abstract base class did in my first C++ rewrite. All I need to do is make sure that whatever the specific implementation I have for a reader (e.g., Siemens PTR format or very old CTD format, Mayo Clinic’s proposed “Battelle” format, new formats that may arise, etc.), fulfills a “RawReader” interface. RawReader at this stage really only has two methods: ReadProjection() and ReadGeometry(), which are actually their own interfaces: ProjectionReader and GeometryReader. This allows me an enormous amount of flexibility in specifying where the data comes from, and indeed even sets me up for streaming projections into a reconstruction real-time since all of this is heavily based on io.Reader and io.Writer, two other well-known Go interfaces. To perform a reconstruction, we’ll just need to pass in some struct that fulfills the RawReader interface and then the reconstruction won’t care how it gets the data, it’ll just know to ReadProjection() whenever it’s ready. Slick.
Go’s abstractions here really simplify the re-usability of these constructs. This is not to say that the C++ version wouldn’t have been as good or as flexible, but Go’s approach here (and the ability to back everything with io.Reader and io.Writer ultimately) allows for so much simplicity. It’s also significantly less code the C++ version to accomplish the same thing. What took me a week in C++, I’ve managed to put together in 24 hours in Go.
So what’s the loss for Go? Speed.
I’ve noticed the hit most prominently reading large float arrays (~4GB) from disk. In C++ it takes ~200ms, and in Go it takes between 2 and 4 seconds. That’s not too surprising, particularly since Go is doing additional work with type validation and parsing endianness that wasn’t in my original C++ rewrite (which, although slower, is actually kind of another win for Go). I’ve dabbled a little bit trying to optimize it using a buffered read, but didn’t gain much as you end up having to still make a copy data during conversion to preserve type safety.
Although the performance difference here was bigger than expected, I think for the time being I’m just going to leave it as is since we do gain quite a bit of functionality. Casting that array pointer is just so tempting though… :)
2022-07-02
Having written a lot of C/C++ that I wanted others to use, dynamic linking as long been a thorn in my side. Although I’ve gotten to a point that I can resolve pretty much any issue I run into with it, it’s still a major barrier to entry for many folks. I’m writing specifically about my software FreeCT, which, owing to a CUDA dependency and the fact that it was written 10 years ago, is a lot of C++.
Initially, I didn’t use any external libraries (other than CUDA’s). Eventually though, I introduce yaml-cpp (about as lightweight and unoffensive of a library as possible), then Boost (good, but heavyweight and somewhat offensive), and finally DCMTK (ugh). That being said, all of these libraries are available through apt, and I provided instructions on how to install them first, prior to the 3 line compilation commands so I figured most folks would be able to figure it out.
I was wrong.
When DCMTK introduced a frivolous (ok, it’s probably not), breaking change to their dictionary reading API with no backwards compatibility, folks were hamstrung to compile the library on their own. If they weren’t on the latest version of ubuntu (which I did specify in the requirements, but who reads those…), I was getting an email. And, while this is a relatively easy fix on Linux, many Windows folks wanted something native that they could run, which I was never going to deliver.
There are so many strong opinions on the “right” way to do linking. Here’s one “proving” static linking is the worst. Here’s one quantitatively arguing the dynamic linking is, at best, unhelpful and at worst, harmful.
To me though, the whole argument is one of those the “right” answer versus the “real” answer kind of things. Practically speaking, the benefits of dynamic linking, particularly for uncommon, domain-specific libraries like DCMTK, just don’t pan out and actually present an obstacle to portable, easy-to-use software. Indeed, I’d argue that most software (that doesn’t arrive through a system’s package manager) typically ships with a collection of some shared libraries! It’s so stupid! This has to be done though since there’s no other way to guarantee that your binary can find the necessary linked libraries and versions it needs on the target system.
I’ve read the counterpoints to static linking, and grok all of them, but you know what? When I ship my statically-linked binary it just works. No fussing, no mess, etc. That’s why I’m porting the FreeCT project to Go. I’ll still have to provide a few compiled shared libraries for the GPU code, but ultimately I get to provide my potential end users with software they can actually use.
2022-01-23
This topic keeps coming back.
My current opinions on it are informed by very recent concrete work experience wrangling the issue of environments. Previously, they were more based on frustrations and intuition with the state of trying to run my software in any sort of “general” way.
In the world of large, distributed systems Docker is an incredible tool. A dockerized version of your application is less of an application solution and more of an environment solutionthat just happens to also contain an executable of your application inside of the container. It never would’ve been possible in an age before gigabytes of RAM and multicore processors, but for our modern era of computing, I think it’s one of, if not perhaps the most, powerful tool that we have.
Although Docker can occasionally feel like overkill, I think it’s the solution that we’ll all ultimately use going forward. Especially as we begin to optimize the overall Docker program, ecosystem, and also the individual containers more going forward.
In a more abstract direction, there’s also an interesting self-similarity in containerization as well: a mini-copy of a computing environment within a parent computing environment. As computing evolves, I’ll be curious to keep studying the extent to which this phenomenon continues. Biological systems also display self-similarity and also have to contend with regulating their environments and the cooperation of inter-connected components through physical, chemical, or structural interfaces. As computing evolves, I can’t help but see more and more overlap in these two worlds.
I strongly believe that we are on the cusp of being able to apply these biological concepts to vast networks of computers to better understand their dynamics and self-regulation (or lack thereof), but also how to predict their behavior and consequently improve them. To lean perhaps too much on the metaphor: computing has for a long time been a primordial soup of single-celled (single cored? single-threaded or gently multi-threaded?) processes (i.e. computing “prokaryotes”) and devices floating around and occasionally aggregating into larger, more powerful and capable systems (i.e. computing “eukaryotes”). As modern technologies evolve to simplify this aggregation process (e.g., Kubernetes), I think we’re currently witnessing the very real emergence of what can be thought of as eukaryotic computing.
Tools like Kubernetes are exploiting the self-similarity enabled by Docker to make this evolution easier. Consider the idea that many “nodes” used by Kubernetes are actually virtualized machines living in a datacenter, and suddenly we see a whole new layer of self-similarity. This represents a slick evolution over the older scientific clustering tools like HTCondor (https://htcondor.org/). Using HTCondor as an example: no environment management for distributing jobs is provided, only environment selection and whatever provi
2021-05-09
This is not a particularly academic topic, however I’d guess it’s relevant to most people these days. I recently took over as the team lead for the backend engineering team of our project at Magic Leap and have been running myself pretty ragged keeping up with everything. When I started these “nuggets” exercises, one of the express goals was to actually set aside some time to deliberately think about other things than work, but I’ve really let that slip since stepping into the new position.
I mainly want to note how drastically different I feel than when I first started these writings (if for no one else than myself!) The biggest thing I’ve let change is (1) setting aside time to go for a walk in the morning and (2) neatly wrapping up at the end of the day around 6pm, putting everything away and transitioning into my evening. In the new role I participate in way more meetings, and given that Magic Leap is a pretty global workforce, meetings don’t always allow me to cleanly begin my day at 9am and then cleanly wrap up at 6pm. I’ve started to notice that I’m getting pretty burned out.
Everyone has to find the balance that works for them I guess. I’m envious of my colleagues who can churn out high quality work at all times and seemingly endlessly, but the longer I do this the more that I realize my best work comes from being well rested and allowing my brain to do other things (exercise, woodworking, building things, homelabbing, cooking, etc.) I can’t fully explain why, but the deliberate putting aside of my work somehow helps me do my job better. Then, when I’m “in it,” I’m REALLY in it. And when I’m not, I have the capacity and energy to get excited about going back to “it.”
I’m still new to the position, and we’re still charting a new course with our work and redirecting the ship to follow that course, which has been a ton of work. I could burn the candle at 18 ends, but there will be things that don’t get perfectly wrapped up. This is a thought that I’m having to get used to and is, frankly, very new to me. I think there will definitely be a bit of a transition back to “normal” as I find that balance point. I hope that it comes sooner rather than later though!
As of today, I’m taking some concrete actions to shift things back a bit in the direction I need them to go:
- Carve out 45 minutes on my calendar for lunch every day
- Get back to getting up early enough to walk (been letting that slip a bit)
- End my workday after 8 hours (unless there is a really really good reason to not do so)
Those little things seem to help a ton back in January and February, so putting them back at top priority is the right call.
2021-03-21
The nature of my job has recently changed, and I’ve inherited a pretty major project and an extremely compressed timeline in which to deliver it.
One critical component to our success will be thorough and pervasive automation, which we currently lack, but which free us up to actually implement the core technology. Having worked in software development long enough now, I know that automation is a huge piece of the puzzle, not only with respect to long-term project success and maintainability, but also in terms of the amount of work it can take to set up correctly. And certainly not just automation around building your software, but also in testing it, and deploying it.
There are many considerations to make around automation (which tools to use, proper setup, etc.), but two risks I haven’t seen discussed very much are (1) automating too early in the project (2) not automating early enough. The game you’re playing is evaluating whether or not it’s worth the time and energy to configure the kind of pervasive automation people expect these days for your project, on the off chance that other people become interested in it. But automate too late and you’ll find yourself unable to deliver on “acceptable” timelines, or delivering software with mistakes in it (“did I remember to ‘git pull’ my main branch before I built that last binary I sent to $megacorp?”).
I think there’s an argument to be made that from day 0 of any project, you should have set up continuous integration and continuous delivery, even if there’s no actual testing and you’re just making sure the software still builds. Modern tools in Github and Gitlab are making this easier and easier every day, and slightly more out of date tools like Jenkins are still fine, but typically too much work to bother setting up for a small-scale software project.
On the other hand, all of these automation pipelines take a decent amount of labor to configure. If you’re only ever going to be supporting the software for one or two platforms, and you don’t need to work with a lot of other people, a well-written CMake file and a good set of build scripts is almost certainly more than enough.
These days, I’m subscribing to the “let the project tell us” approach. I have found that the single most important pay-off of automation is reducing errors and engineering overhead during the build and deploy process, so at every step if your current automation is adequately addressing those needs, then you should stay the course. As soon as significant resources start getting sucked into those areas, or mistakes start happening, it’s time to refactor your automation and see where it can improve.
The above is not to say that you shouldn’t be assessing the weak points along the way and changing them as there’s time a resources available, but it is saying don’t try and make major automation architecture choices in the absence of (1) knowledge of what you need and (2) an actual need.
2021-03-12
I recently finished rereading Cannery Row, and did a little bit more of a deep dive on the character of Doc, who is based off of one of Steinbeck’s close friends, Ed Ricketts. Although Ricketts was primarily a biologist and ecologist, he wrote a few philosophical essays in his lifetime. One that particularly caught my eye was titled “Nonteleological Thinking” and is purported by Wikipedia to describe “a way of viewing things as they are, rather than seeking explanations for them.”
Now, it’s probably important to note that I have not read any text of the essay that I trust to be 100% accurate. The only online version I have found is this one, which although it has that wonderful early 2000s geocities styling, seems potentially a little suspect as far as the overall quality, accuracy, and detail are concerned. The full essay is supposedly reprinted in “The Sea of Cortez” which I intend to purchase and read, I just haven’t had a chance.
Although I haven’t read the darn thing, the concept of science seeking to describe things as they are rather than seeking explanations for them is deeply interesting. My personal interest stems from coming from labs and fields where that approach is often not regarded as sufficient: particularly math and physics, but a little bit the field of medicine that I was working in.
I think the general assumption these days is that to publish research, we must offer (or more precisely, proffer) an explanation for what we present. We must at least seek to explain the phenomena we observe and wish to describe. But should we? Or at the very least, should our peers require an explanation from us? For instance, Boris Belousov attempted to publish his findings on what would become the Belousov-Zhabotinsky reaction, however his work was rejected because “he could not explain his results to the satisfaction of the editors.” Perhaps there is value is separating the what (i.e. categorizing and describing; the observations) from the why (i.e. the explanation for the observations).
It’s a complex topic. These days, people try to publish a significant amount of poor-quality, if not downright misleading, research. I understand that we have to filter somewhere, however I guess I’m thinking that maybe publishing observations (depending on the field, repeatable observations) could be just as valuable and important as explanations.
… I’ll read the essay though and see if I’ve completely misunderstood what Rickett’s was trying to go for.
I mostly write C/C++ code when playing around with toy model physics simulations, such as the lattice Lotka Volterra simulation.
For a long time, a sorely lacking feature of C++ has been a means to do simple visualizations, such as simple 2D lattices. You first have to figure out a windowing system that will play nicely with whichever system you’re currently running on (such as GLUT, GLFW, X11, Cocoa, whatever Window’s windowing system is called, etc.), then you have to learn some basic graphics programming to get OpenGL, or Vulkan, etc to render a quad, then push a texture into that quad… All a bit daunting for a beginner, isn’t it? It’s all still a bit daunting for me and I’ve been programming and doing science for about 15 years now.
Although languages like javascript and MATLAB are easier to get up and running, their speed is woefully inferior to C++.
I won’t beat around the bush here: the solution to this problem is the OLC Pixel Game Engine, a single-header file, simple game engine that allows you to run simple, cross-platform visualization from C++ code. Put together by David Barr and the community around his YouTube channel One Lone Coder, it truly is an extension that was desperately needed for C++.
I won’t go into details about how to use the OLC PGE (those are covered in the Github), I just want to give it my ringing endorsement.
As a further shout out, check out David’s excellent C++ tutorials from a game development perspective. Although building games is the focus, there’s tons of great info for just about any domain.
2021-02-23
After last week’s post, I’ve gotten it in my head that it would be fun to stand up a second network, in parallel with the current one, for experimentation. I’m striving for the smallest, lowest-power solution that I can while still preserving all of the functionality of the current network (and improving on a few things).
The current home network uses the following:
- Primary router/firewall (runs two networks: LAN and DMZ)
- LAN switch/secondary router (Ubiquiti EdgeRouter 12)
- Wireless AP
- NAS
- Webserver
Setting the above up was mainly me experimenting: realizing I wanted to try new things, adding on, repurposing, etc. For instance, the EdgeRouter 12 was originally a swiss-army-knife for our network that basically handled everything for us. Although it could still realistically function as such, my preference is to have a dedicated router, and run managed switches off of that. I also don’t think I could go back to EdgeOS after using PfSense. The PfSense box was added as an afterthought, when I felt like it was really important to have a two-firewall DMZ (only to realize that that thinking is a bit out of date these days).
Other complaints about the current network:
- DMZ should have its own managed switch
- Complete underutilization of the 1U, 8 Core SuperMicro server (SYS-5019A-FTN4, currently the main router on our network)
- Only 1 POE port for LAN
- Switch on EdgeRouter 12 is full
- Could be lower-power
I’ve gone ahead and ordered the following:
- Main router: Netgate SG-1100
- LAN Switch: UniFi Switch Lite 16 PoE
- DMZ Switch: UniFi USW Flex Mini
- NAS Replacement: SuperMicro SYS-5019A-FTN4 with an IcyDock 4 SSD cage (yes I ordered a second one of these! They’re awesome little appliances!)
- Wireless AP: UniFi 6 Lite Access Point
2021-02-17
I’ve been really getting into spreadsheets lately. I’m a firm believe in not using spreadsheets for “real” tasks, by which I mean anything you can’t manually verify all of the data on your own if need be, however I’ve started using them more and more to gain insight into day-to-day things like (1) how much I’ve spent on computers over the last year, (2) splitting utility and grocery costs with my girlfriend, and (3) evaluating the actual cost of running this website on my own hardware instead of via 3rd party hosting or the cloud. That last one is what I’m going to discuss today.
Let me start by saying that for most folks, it’s completely impractical to host your own website on your own hardware and services like Squarespace are more than worth the money. My needs on the other hand aren’t especially well served (pun intended) by those services. I like a challenge, but is it completely financially irresponsible to bother with my own hardware?
There are a few numbers to consider here: (1) the up front cost of the necessary hardware and (2) the monthly power costs of keeping computers on 24⁄7. For this site, I’m running two machines that I would otherwise not be:
- A supermicro 1U network appliance as an appropriately-secure firewall for the network
- A 65W TDP, AMD-based small-form-factor desktop machine
One of the biggest benefits of the cloud is that you don’t have to purchase hardware, so if I’m saving anything on a monthly basis, we need to weigh that against that up front cost number.
Long story short (I’ll spare you the calculations), I figure the power cost here in LA for those two machines is roughly \(60-90 per year. Using something like a Digital Ocean, low-end droplet I could spend ~\)60 a year to host my site, with no hardware costs (and no real risk to our home network). So… at best we’re probably breaking even. Bummer.
While the numbers probably aren’t going to ever work out for my personal site, I’ve been brainstorming ways to offset those power costs though:
- Lower-power machines
- Cloud hosted (ugh)
- Offer to host the websites friends for 1⁄2 of what other services do (~$40 per year)
The last one seems a compelling option: I’d get to play around with other technologies than Django (mostly Wordpress, if I had to guess), I’d actually have some “stakes” if the server goes down, etc. And I would only need two people before I’m basically offsetting the entire power cost. Even still, it would take me 18 years of such an arrangement to recoup my up front costs for the hardware. Whoops.
Although in the long run I’d probably save money running this in the cloud, I still think I prefer hosting my own. I like that I’m hosting my own, and if nothing else, that’s worth $30 for entertainment value every year!
{% load latexify %}
While I’m generally only intending to do these once a week, doing a couple extra over the next week or two will help me organize my thoughts about where to go with the Lotka-Volterra simulations, and hopefully bring it back to where the whole effort started.
I have a solid working version of the Makeev et al. paper that I referenced a few posts back. While I’m able to reproduce the phenomena they discuss (wave fronts, spiral waves), I’m unable to do so on the lattice sizes and time scales used in the paper (4000x4000 grids, ~10^5 Monte Carlo steps).
It’s possible that they just set one 4000x4000 grid to run on their fastest single-core machine and let it run for a couple of months, but I doubt that. Even my 1024x1024 grid sample that I’m running has taken two full days and we’re only on MC step 571. I discussed previously that it seems like the partial sums/calculation of the cumulative function is the limiting step, however also worth noting is that as the grid fills up, the update increment gets smaller since {% latexify ‘\Delta t \propto \frac{1}{N{pred} + N{prey}}’ math_inline=True %}.
To accelerate things, I have already tried to following:
- Store a map of occupied cells, only iterate over occupied cells. (faster until the grid starts to fill up) <\li>
- Instead of iterating over the entire grid, only compute the KMC update for a single randomly selected occupied cell (fundamentally flawed, also breaks KMC’s “physical” time step) <\li>
- The random update scheme employed by Chen and Teuber (too slow, slower than my current implementation of Makeev et al.)
I’ve looked around a little bit and haven’t been able to turn up much research on accelerating kinetic Monte Carlo, and the research I can find seems to be quite domain-specific. Although I still think that Makeev et al. has some sort of more efficient approach that I’m missing, overall I think I’m in the correct ballpark. After rereading the paper and a few others by the same folks, the “set it and wait” approach seems to be not entirely unlikely.
I’m a little torn now about where to go next. Part of me wants to continue to try and speed up the simulation, but another part of me wants to play around with extending it to a third species and coming back to where this all started: seeing if specialization is an emergent phenomenon of competition. Both are worthwhile, and realistically maybe I’ll stumble across some new acceleration if I work on something else for a bit.
2021-02-09
I was going to write about optimization approaches I’ve considered or am considering for my Lotka-Volterra simulations, but I actually feel like I can’t not write about a very important programming lesson: don’t roll your own.
I recently read an interesting article from Joel Spolsky (co-founder of Stack Overflow) about why you never ever thrown out your entire code base and start again. The lesson of the post is that every code base inevitably gets to be a spaghettified nightmare, but that nightmare holds countless hours of bug fixes, knowledge, and creative problem solving that is powerfully valuable and should not be ditched if at all possible. To use his words:
It’s harder to read code than to write it. “
But, if there’s one thing that I’ve learned in my short time in industry, it’s that he’s right on both fronts: every code-base I’ve ever walked into is a “shitshow,” and it’s always way harder to unravel someone else’s code than it is to write my own from the ground up. That being said, I’m coming around to (1) perhaps I’m the shit show (or rather, all people who program kind of are), and (2) although every code base is kind of a shit show, most of the folks in this line of work are fairly competent and put some thought into what they’re doing, it can sometimes just be difficult to tease out.
This week I’ve been unraveling hardware video codec wrappers for different platforms written by colleagues. My first thought was “this approach is pure insanity!” but after sitting with it and taking the time to unpack it, I realized that other than some confusing variable names, it was very thoughtfully implemented and addressed use cases that our other implementation had failed to even consider. Consequently, those missed use cases are the reason I’m even having to go back and unravel everything and merge the two, now disparate, implementations.
I won’t belabor the point too much, but I just want to second that indeed although it’s easier and more fun to write your own… don’t. Barring some edge cases, or unforeseen use cases, lean on the countless hours of effort those before you put in. It doesn’t make you less of a programmer, it just frees you up to focus on newer, more exciting ideas.
As a final addendum though, I will circle back to the importance of documentation (and to a lesser extent, commenting your code). So much confusion can be addressed by one sentence clarifying why you’re doing what you’re doing, or one document for a project explaining the overarching goals and use cases you’re programming for. However self-documenting you think your code is, it’s not.
{% load static %}
I’ve been working on implementing several variations of a more “true” lattice Lotka-Volterra simulation than the one I posted last week. One of the most compelling versions I’ve come across is the simulation described in this paper from Makeev et al. that employs “rejection-free” Monte Carlo, wherein we consider all possible updates to the system and then only have to throw one random number to determine which update occurs. This is in contrast to something like Chen and Teuber employ, which involves throwing a lot of random numbers to determine whether or not an event occurs (rejection-ful?). With rejection-free MC, we don’t throw any time steps away, at the cost of having to inspect the entire array for each time step.
By and large I’m able to replicate the phenomena described in Makeev et al (and will hopefully work on a version I can post here soon), however the one place I can’t quite touch them is their array size. They describe arrays up to 4000x4000, which I can definitely simulate, it’s just so slow. Although we could just let it run for a couple of weeks and save every MC step, I’d much rather have something that can run fast enough to be fun to watch.
Long story short, I’ve narrowed the bottleneck down to the step where we compute the non-normalized cumulative distribution function for the system. I could optimize everything else away, but I don’t think I can get away from this.
I’ve spent this week benchmarking my original implementation against C++ STL’s implementation of the std::partial_sum() algorithm against MATLAB’s “cumsum()” implementation. They all do exactly the same thing, but at first it seemed like the MATLAB implementation was much faster than the other two, but that turned out to not be the case. No surprise that my naive implementation was the slowest (but not by too much), MATLAB was second, and std::partial_sum ended up being the fastest.
Results are below. I’ve left my naive implementation out in favor of the other two for brevity. I think that despite my best efforts (randomizing, hitting others arrays after filling but before computing, etc.), we are seeing some cache effects in the 512x512-1024x1024 range (the L1 cache on my machine is 512kB, so this range would make sense).

I’ve never taken an algorithms class but I think that if a vector/array has N elements, then partial sums is O(N) no matter what, and no amount of parallelizing or cleverness will save you. I have a couple of ideas, but I think 19ms is how long each update takes!
Over the last week I’ve been working on simulations of Lotka-Volterra on a lattice. I took a crack at what I would do without reading anything or looking at anyone else’s work and ended up with something I’m neither perfectly happy with or terribly dissapointed by. My approach was to set out the following rules:
- Each cell has a carrying capacity of predators and a carrying capacity of prey
- Each full step of the simulation consists of an "update" step, where the individual populations of each cell are updated based on the current populations, and a "migrate" step, where populations are updated based on neighboring populations.
- At the end of each step, any cells with populations above the carrying capacity are truncated down to the carrying capacity (i.e. animals die off by overpopulation)
Coloring in the above simulation is green for “prey” and red for “predator”. Brighter colors mean that the species are closer to the carrying capacity for that cell. Cells that are white® mean that both species are close to their carrying capacity for that cell. Check out the page source code to see more details of the simulation.
No doubt this approach was informed by my recent experimentation with Lattice-Boltzmann fluid simulations, where a similar approach to “update” and “translate” (in LB-terms: collision and streaming) is used to carry out the simulation. The big difference between the two though is that LB tends towards and equilibrium, while Lotka-Volterra has no such requirement (although perhaps it would be interesting to implement such a hybrid Lotka-Volterra/Lattice-Boltzmann model!). What we end up with are essentially autowaves, the active medium for which is the exponential reproduction of the prey species.
I haven’t spend enough time with this simulation to really understand if it has any physical value whatsoever, however interestingly the annihilating wave-fronts bear a strong resemblance to those that occur in other autowave phenomena such as the Belousov-Zhabotinsky reaction. To see the reaction in action check out this youtube video.
After a little bit more research though, this is very much not the standard approach for Lattice-Lotka-Volterra simulations. The more common approach is Monte Carlo simulations and a lattice that is defined very differently from how I have defined mine (and which I will write about in the future, along with a simulation). While I don’t think that my approach is entirely invalid, I will need to do more work to figure out how the two are related (if at all).
2021-01-19
{% load latexify %}Today’s post is going to be my first of “it’s late and I forgot to start this earlier.”
I want to talk about the Lotka-Volterra Equations vs Competitive Lotka-Volterra equation and whether or not either really apply to my goals of seeing if specialization emerges from competition.
The short answer? I doubt it, but there’s a chance. I am working on what I think will be a cool simulation of standard (i.e. non-competitive) Lotka-Volterra on a 2D grid, which I’ll hopefuly post in the next week or two, but first down to business:
Standard Lotka-Volterra equations are as follows:
{% latexify ‘\frac{dx}{dt} = \alpha x - \beta x y , \frac{dy}{dt} = \gamma x y - \delta y’ math_block=True %}
I’ll direct you to the wikipedia for an in-depth unpacking of what the terms mean (I only have 30 minutes here), but suffice it to say that the “prey” population (x(t)) is depends on an intrinsic growth rate (alpha), and a predation rate (beta), while the “predator” population depends on an intrinsic death rate (gamma) and its own predation rate (delta). The predators benefit from predation, while the prey are hurt by it. This creates what you might expect where predators and prey have boom and bust cycles. The underlying population growth model is exponential (i.e. nothing limits the population other than predation and prey availability).
Competitive Lotka-Volterra uses a logistic population model:
{% latexify ‘\frac{dx}{dt} = r x \left(1-\frac{x}{K}\right)’ math_block=True %}
which does have an inherent carrying capacity. Competitive Lotka-Volterra then encodes the impact species have on one another via a constant, alpha, which also encodes the carrying capacity. For a system of N species, we get the family of differential equations:
{% latexify ‘\frac{dx_i}{dt} = r_i xi \left(1-\sum{j=1}^N \alpha_{ij} x_j\right)’ math_block=True %}
So are these equations capable of interrogating whether or not specialization is an emergent phenomenon of competition? For the standard Lotka-Volterra equations, I think not. Nothing about them encodes an evolution in the species other than population, and the two species do not compete for a shared resource. Competitive Lotka-Volterra might have some legs though. Since {% latexify ‘\alpha_{ij}’ math_inline=True %} encodes the impact species i has on species j (negative), we could perhaps build in some time depence to alpha and examine the long term behavior of the alpha matrix. If specialization is an emergent phenomenon of competition, we would expect that over time, species that start out as generalists (all alphas in their row are equal) would start to focus on one or two other species.
It’s not much, but it does give us an angle to attack the problem.
2021-01-17
I wasn’t going to actually upload this, but I’ve spent enough time getting it working that now I’m feeling a little inspired to push it out there. It seems appropriate for a sort of “hello, world!” first sample simulation. In the future I’m hoping to post more simulations. This is just intended to make sure I had the infrastructure up and running to keep the simulations in the database and automatically populate them.
My initial idea to enable/disable the simulation when the panel expands didn’t pan out, since that sort of thing isn’t supported by the HTML standard. Then I realized that my existing design pattern would quickly result in conflicts between simulations as time went on. Finally, after some thinking, I think I’ve settled on something that should withstand the lifespan of this website and the number of simulations I hope to do. Object-oriented programming for the win!
In the long run I think I’ll more than likely (need to) change some things around about how I’ve done this, but for the time being this should do nicely. My goal for the near future is it do enough, and add enough new stuff that the performance becomes unacceptable.
My first exposure to research in undergraduate years was with none other than the man who inspired the name of this particular page: Dr. Royce Zia. In particular, he introduced me to the concept of emergent phenomena: the idea that “microscopic” individual components, when collected together under certain physical circumstances can display behaviors and properties that the individual components do not actually possess. Indeed these concepts lie at the center of statistical mechanics. For instance, a water molecule by itself doesn’t know what ice is, or steam, or water. It is only when grouped together among many other molecules that these properties (states) emerge as a function of pressure, and temperature.
It doesn’t just have to be literal microscopic things: starlings flocking, traffic jams, sand, and other very macroscopic things display emergence. The individual in no way is specifically programmed (nor capable of) with the complex behaviors that the group displays. One of my favorite aspects of emergent phenomena is that they’re typically fun and fairly easy to simulate. A key idea is that the individual is programmed with simple rules, and then, when aggregated together with a bunch of other individuals obeying the same rules, you get emergence.
Perhaps the most classic example is Conway’s The Game of Life (Dr. Zia was the first to introduce me to GOL). Everything we observe from the game of life is coded into only three rules (click the link).
So where am I going with this: after my post last week, where I mentioned that with software we are often forced to either specialize, and write software for a few specific environments, or we must generalize and essentially provide our own environment, it got me thinking that perhaps specialization is an emergent property of competition in a population, and if so, could we model it either mathematically or with a simple simulation?
I’ll confess that I don’t have an answer to either of those questions yet, but given that a population model as simple as the logistic map displays emergent, chaotic behavior surely we can find something similar (or at least look) that displays some interesting behavior. If I stay curious about this whole specialization thing, I may just have more to say about it in the next “nugget.”
I’ll confess that my interest in this is also somewhat personal these days: I have personally resisted specialization in my computing habits, but I’m at a point in my career where more and more forces are pushing me to specialize. Particularly around use and knowledge of gaming engines. The engines really really help solve the environment problem and offload signficant amounts of boilerplate coding that, it’s true, I just don’t want to do.
(But do I really have to learn Uniityyyy?)
2021-01-05
I have, for a long time, taken for granted the concept of an “environment” in computing. It is only more recently having run up against this when trying to distribute software that I’ve written (e.g., FreeCT, and some pull requests I’ve submitted to the OLC Pixel Game engine) that the world has really pressed upon me the importance of the environment in which we’re trying to compute. To be honest, I find the whole reality of trying to distribute the stuff that I program in any “easy-to-use” way deeply frustrating and have not found a good, generalizable solution.
The most obvious computing environments are Mac vs Windows, the operating system of a computer. Although it’s an oversimplification, an operating system is really just a conglomeration of software, programs, and libraries, that get your computer turned on and, well, computing. In certain instances, they provide a blueprint for adding new software: a package manager. The package manager tells the new software what libraries it can count on being there, and how and where to install it in the operating system. Modern app stores are a frienly(ier) version of this. When you can count on things being where they’re supposed to be, and an environment looking like it should, software is MUCH easier. That’s perhaps Apple’s biggest win of all time. Control the environment, control compatibility, make the user happy.
What about cross platform software? The general pattern that I’ve observed here is that this software typically bundles everything it needs inside of itself. Like a little cell or amoeba, it knows it has everything it needs and where to find it, all it needs is some water to float around in and sip power from. It’s less efficient that the system-level packages, but does seem to work. The inelegance of this frustrates me though. I’m not 100% sure why.
There are layers too: while most folks understand the Mac/Windows example, most are blissfully unaware of the underlying machine instruction set on which the software runs, which defines its own, lower level environment. These machine-level instructions are the ACTG amino acids of DNA, but for source code. Thinking about it like that I can’t help but come around a bit on my frustration with environments: of course running programs natively in different environments doesn’t work! We wouldn’t take DNA from a peach, put it into a plum and expect it to start making peaches!
So I’m not 100% sure what the solution is. You gotta pick the environment and run with it, I guess. Specialize. That or build your own and live free or die! Although language-level package managers are outside of the scope of this chat tonight, that is a fairly elegant solution… however as primarily a C++ programmer, it’s a fat lot of good language-level package managers do me.
I don’t think it’s going to be resolved anytime soon. I’d also like to have a better grasp on DevOps pipelines, but just haven’t had the time. One day…